Allgemein
(Danke an Denise, Lysander und May fürs Korrekturlesen)
Das hier ist eine interaktive Formelsammlung mit allen wichtigen Formeln der Diagnostik 1 Vorlesung. Zu den meisten Formeln und Tests ist der entsprechende R Code beigefügt, den ihr direkt auf der Website ausführen könnt. Dafür einfach in den entsprechenden Feldern eure eigenen Werte einsetzen und auf Run Code klicken. Mit dem Start Over Knopf bei den Codeblöcken könnt ihr diese zurücksetzen.
Nur für den Fall, dass mein Server gerade brennt: Download R Markdown Files. Entpacken, mit R Studio öffnen, install.packages(c("shiny", "learnr")) in der R Konsole ausführen, dann Run Document.
Inhaltsverzeichnis
- Grundlagen
- Modelle
- paralleles Modelll
- essentiell paralleles Modell
- tau-äquivalentes Modell
- essentiell tau-äquivalentes Modell
- t-kongenerisches Modell
- mehrdimensionales t-kongenerisches Modell
- Skalierung
- Parameterschätzung
- Faktorenanalyse
- Grundbegriffe
- CFA vs EFA
- Modellevaluation
- Rotation
- Reliabilität
- paralleles Modell, essentiell paralleles Modell
- tau-äquivalentes Modell, essentiell tau-äquivalentes Modell
- tau-kongenerisches Modell
- Allgemeine Methoden
- Validität
- Faktorielle Validität
- Konstruktvalidität
- Kriteriumsvalidität
- Einzelfalldiagnostik
- Normwerte
- paralleles Modelll
- essentiell paralleles Modell
- tau-äquivalentes Modell
- essentiell tau-äquivalentes Modell
- t-kongenerisches Modell
- Interpretation
- Hypothesen
Grundlagen
Zufallsvariablen
\(\large X_{\text {iPerson }}\): Eine feste Person antwortet auf ein Item i eines Tests.
- Konstante \(\large E\left(X_{i P e r s o n}\right)=\tau_{i P e r s o n}\): wahrer Wert der Person (zudem eine Realisierung des zufälligen wahren Wertes \(\large \tau_{i}\))
\(\large X_{i}\): Eine Person wird zufällig aus einer Population gezogen und antwortet dann auf ein Item i eines Tests
\(\large \tau_{i}\): (Zufälliger) wahrer Wert, den die zufällig gezogene Person auf Item i haben wird (Eine Person wird zufällig aus einer Population gezogen, antwortet noch nicht auf Item i) - Realisation ist nicht beobachtbar
\(\large \theta\): zufällige latente Variable (Realisation: \(\theta_{\text {Person }}\))
item_answers = c(5,6,7,8,9)
mean(item_answers)\[\large \operatorname{VAR}\left(X_{i}\right)\]
item_answers = c(5,6,7,8,9)
var(item_answers)\[\large \operatorname{Cov}\left(X_{i}, X_{j}\right)\]
items_answers = cbind(
c(5,6,7,8,9), # item1
c(1,3,10,0,1), # item2
c(1,3,1,3,5) #item 3
)
cov(items_answers)\[\large \operatorname{Cor}(X, Y)=\frac{\operatorname{Cov}(X, Y)}{\sqrt{\operatorname{Var}(X) \cdot \operatorname{Var}(Y)}}\]
covXY = 3
varX = 4
varY = 6
covXY/sqrt(varX * varY)Axiome der Testtheorie
Axiom 1
Für jedes Item \(i\) ist \(\tau_{i}\) die Zufallsvariable, deren Realisation der wahre Wert \(\tau_{\text {iPerson }}\) der Itemantwort der zufällig gezogenen Person ist
Axiom 2
Für jedes Item \(i\) ist die Fehlervariable \(\varepsilon_{i}\) eine Zufallsvariable, die wie folgt definiert ist: \[ \large \varepsilon_{i}:=X_{i}-\tau_{i} \]
Folgerungen
\[\large X_{i}=\tau_{i}+\varepsilon_{i}\]
\[\large E\left(\varepsilon_{i}\right)=0\]
\[\large E\left(X_{i}\right)=E\left(\tau_{i}\right)\]
\[\large \operatorname{COV}\left(\tau_{i}, \varepsilon_{i}\right)=0\] \[\large \operatorname{COV}\left(\tau_{i}, \varepsilon_{j}\right)=0\] \[\large V A R\left(X_{i}\right)=V A R\left(\tau_{i}\right)+V A R\left(\varepsilon_{i}\right)\]
Modelle
\[\large X_{i}=\sigma_{i}+\beta_{i} \cdot \theta+\varepsilon_{i}\]
Wenn ein strengeres Modell gilt, dann gilt immer auch gleichzeitig jedes weniger strenge Modell. Andersrum gilt dies nicht.
Paralleles Modell
Annahmen:
\[\large {\color{green} {\tau_{i}=\theta }} \text{ und somit } {\color{green} {X_{i}=\theta+\varepsilon_{i}}} \text{ für alle Items } i\]
\[\large \operatorname{VAR}\left(\varepsilon_{i}\right)=\operatorname{VAR}\left(\varepsilon_{j}\right) \text{ für alle Itempaare } i, j\]
\[\large \operatorname{COV}\left(\varepsilon_{i}, \varepsilon_{j}\right)=0 \text{ für alle Itempaare } i, j\]
Folgerungen:
\[\large \tau_{i \text { Person }}=\theta_{\text {Person }}=\tau_{j \text { Person }}\]
\[\large \beta_{i} = 1\]
\[\large \sigma_{i} = 0\] \[\large \operatorname{COV}\left(X_{i}, X_{j}\right)=\operatorname{VAR}\left(\tau_{i}\right)\]
Essentiell paralleles Modell
Annahmen:
\[\large {\color{green} {\tau_{i}=\sigma_{i}+\theta}} \text{ und somit } {\color{green} {X_{i}=\sigma_{i}+\theta+\varepsilon_{i}}} \text{ für alle Items } i\]
\[\large \operatorname{VAR}\left(\varepsilon_{i}\right)=\operatorname{Var}\left(\varepsilon_{j}\right) \text{ für alle Itempaare } i, j\] \[\large \operatorname{COV}\left(\varepsilon_{i}, \varepsilon_{j}\right)=0 \text{ für alle Itempaare } i, j\] Festlegungen:
\[\large E(\theta)=0\]
Folgerungen:
\[\large \tau_{i \text { Person }}=\sigma_{i}+\theta_{\text {Person }}\]
\[\large \beta_{i} = 1\]
\[\large E(X_{i})=\sigma_{i}\] \[\large \operatorname{COV}\left(X_{i}, X_{j}\right)=\operatorname{VAR}\left(\tau_{i}\right)\]
tau-äquivalentes Modell
Annahmen:
\[\large {\color{green} {\tau_{i}=\theta }} \text{ und somit } {\color{green} {X_{i}=\theta+\varepsilon_{i}}} \text{ für alle Items } i\]
\[\large \operatorname{COV}\left(\varepsilon_{i}, \varepsilon_{j}\right)=0 \text{ für alle Itempaare } i, j\] Folgerungen:
\[\large \tau_{i \text { Person }}=\theta_{\text {Person }}=\tau_{j \text { Person }}\]
\[\large \beta_{i} = 1\]
\[\large \sigma_{i} = 0\] \[\large \operatorname{COV}\left(X_{i}, X_{j}\right)=\operatorname{VAR}\left(\tau_{i}\right)\]
Essentiell tau-äquivalentes Modell
Annahmen: \[\large {\color{green} {\tau_{i}=\sigma_{i}+\theta}} \text{ und somit } {\color{green} {X_{i}=\sigma_{i}+\theta+\varepsilon_{i}}} \text{ für alle Items } i\]
\[\large \operatorname{COV}\left(\varepsilon_{i}, \varepsilon_{j}\right)=0 \text{ für alle Itempaare } i, j\] Festlegungen:
\[\large E(\theta)=0\]
Folgerungen:
\[\large \tau_{i \text { Person }}=\sigma_{i}+\theta_{\text {Person }}\]
\[\large \beta_{i} = 1\]
\[\large \operatorname{COV}\left(X_{i}, X_{j}\right)=\operatorname{VAR}\left(\tau_{i}\right)\]
tau-kongenerisches Modell
Annahmen:
\[\large {\color{green} {\tau_{i}=\sigma_{i}+\beta_{i} \cdot \theta}} \text { und somit } {\color{green} {X_{i}=\sigma_{i}+\beta_{i} \cdot \theta+\varepsilon_{i}}} \text { für alle Items } i\]
\[\large \operatorname{COV}\left(\varepsilon_{i}, \varepsilon_{j}\right)=0 \text{ für alle Itempaare } i, j\] Festlegungen:
\[\large E(\theta)=0\]
\[\large \operatorname{VAR}(\theta)=1\] Folgerungen:
\[\large E(X_{i})=\sigma_{i}\]
Mehrdimensionales tau-kongenerisches Modell
Annahmen:
\[ \large \begin{gathered} \tau_{i}=\sigma_{i}+\beta_{i 1} \cdot \theta_{1}+\beta_{i 2} \cdot \theta_{2}+\cdots+\beta_{i q} \cdot \theta_{q} \text { und somit } \\ X_{i}=\sigma_{i}+\beta_{i 1} \cdot \theta_{1}+\beta_{i 2} \cdot \theta_{2}+\cdots+\beta_{i q} \cdot \theta_{q}+\varepsilon_{i} \text { für alle Items } i \\ \operatorname{COV}\left(\varepsilon_{i}, \varepsilon_{j}\right)=0 \text { für alle Itempaare } i, j \end{gathered} \]
Festlegungen:
\[\large E(\theta_{l})=0\]
\[\large \operatorname{VAR}(\theta_{l})=1\] \[\large \operatorname{COV}\left(\theta_{l}, \theta_{m}\right)=0 \text { für alle latenten Variablen } l \neq m\]
Folgerungen:
\[\large E\left(X_{i}\right)=\sigma_{i}\] z-Standardisierung:
\[\large Z_{i}=\frac{X_{i}-E\left(X_{i}\right)}{\sqrt{\operatorname{VAR}\left(X_{i}\right)}}=\frac{X_{i}-\sigma_{i}}{\sqrt{\operatorname{VAR}\left(X_{i}\right)}}\]
item_answers = c(1, 4)
vars_items = c(4, 3)
sigmas = c(5, 1)
(item_answers - sigmas)/sqrt(vars_items)beta = 1
var_item = 2
beta/sqrt(var_item)Skalierung
Ein psychologischer Test gilt als skalierbar, wenn die Zuordnung der Messwerte zu den Personen auf der Basis eines empirisch nachgewiesenen testtheoretischen Modells geschieht.
- \(H_{0}\) : Die Folgerungen aus dem Modell sind erfüllt
- \(H_{1}\) : Mindestens eine Folgerung aus dem Modell ist nicht erfüllt
Paralleles Modell
Zu überprüfende Hypothesen:
\[\large \begin{gathered} E\left(X_{i}\right)=E\left(X_{j}\right) \text { für alle Items } i, j \\ \operatorname{VAR}\left(X_{i}\right)=\operatorname{VAR}\left(X_{j}\right) \text { für alle Items } i, j \\ \operatorname{COV}\left(X_{i}, X_{j}\right)=\operatorname{COV}\left(X_{o}, X_{u}\right) \text { für alle Itempaare } i, j \text { und } o, u \end{gathered}\]
Essentiell paralleles Modell
Zu überprüfende Hypothesen:
\[\large \begin{gathered} \operatorname{VAR}\left(X_{i}\right)=\operatorname{VAR}\left(X_{j}\right) \text { für alle Items } i, j \\ \operatorname{COV}\left(X_{i}, X_{j}\right)=\operatorname{COV}\left(X_{o}, X_{u}\right) \text { für alle Itempaare } i, j \text { und } o, u \end{gathered} \]
tau-äquivalentes Modell
Zu überprüfende Hypothesen:
\[\large \begin{gathered} E\left(X_{i}\right)=E\left(X_{j}\right) \text { für alle Items } i, j \\ \operatorname{COV}\left(X_{i}, X_{j}\right)=\operatorname{COV}\left(X_{o}, X_{u}\right) \text { für alle Itempaare } i, j \text { und } o, u \end{gathered} \]
Essentiell tau-äquivalentes Modell
Zu überprüfende Hypothesen:
\[\large \operatorname{COV}\left(X_{i}, X_{j}\right)=\operatorname{COV}\left(X_{o}, X_{u}\right) \text { für alle Itempaare } i, j \text { und o, } u \]
tau-kongenerisches Modell
Zu überprüfende Hypothesen:
\[\large \operatorname{COV}\left(X_{i}, X_{j}\right)=\beta_{i} \cdot \beta_{j} \text { für alle Itempaare } i, j\]
Mehrdimensionales tau-kongenerisches Modell
Zu überprüfende Hypothesen:
\[\large \operatorname{COV}\left(X_{i}, X_{j}\right)=\sum_{l=1}^{q} \beta_{i l} \cdot \beta_{j l} \text { für alle Itempaare } i, j\]
Parameterschätzung
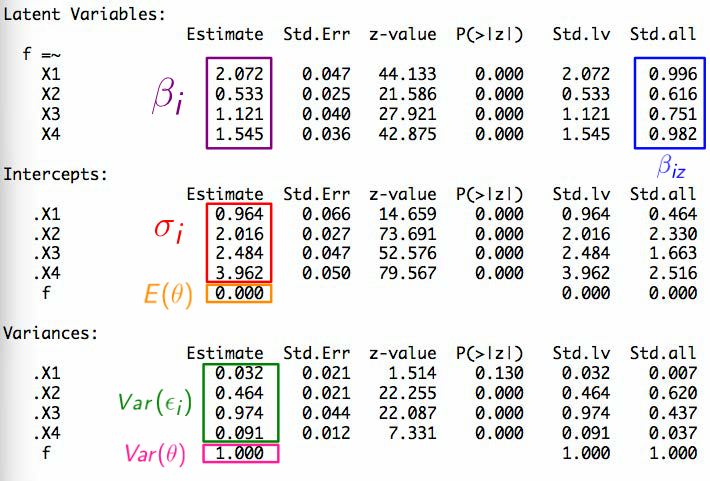
Faktorenanalyse
Grundbegriffe
- Einfachstruktur
- Jedes Item in der Population weißt nur auf einem Faktor einen von Null verschiedenen Steigungsparameter auf.
- Kommunalität \(\boldsymbol{h}_{i}^{2}\)
- Die Summe der quadrierten Ladungen des Items über alle Faktoren der Anfangslösung
- Maß für die „Wichtigkeit“ des Items bei der Interpretation
- Eigenwert
- Die Summe der quadrierten Ladungen aller Items auf diesen Faktoren (SS loadings)
- Maß für die „Wichtigkeit“ des Faktors
- Hauptladung
- ist die Ladung eines Items auf dem Faktor, die am höchsten ausfällt und signifikant ist
- Nebenladung(en)
- sind die Ladungen eines Items auf einem oder mehreren Faktoren, die nicht die höchste Ladung auf dem Faktor darstellen, aber signifikant sind
CFA vs EFA
CFA
schätzt die Parameter eines (nahezu) beliebigen (vorher festgelegten) Testmodells und prüft dessen Annahmen
- Spezifikation eines Testmodelles
- Messmodell = Beziehung manifest-latent: Gleichungssystem
- Strukturmodell = Beziehung latent-latent: Covarianzen
- Wahl einer faktorenanalytischen Schätzmethode (Maximum-Likelihood, WLS, WLSM…)
- Kovarianzmatrix der Items S -> Ladungsmatrix \(\Sigma\)
- Kovarianzmatrix der Items S -> Ladungsmatrix \(\Sigma\)
- Modellevaluation
EFA
schätzt die Parameter eines ein- oder mehrdimensionalen tau-kongenerischen Modells (und prüft eventuell dessen Annahmen). Auch nützlich, wenn Modell in CFA abgelehnt wurde
- Wahl einer faktorenanalytischen Schätzmethode (Maximum-Likelihood, WLS, WLSM…)
- Kovarianzmatrix der Items S -> Ladungsmatrix \(\Sigma\)
- Kovarianzmatrix der Items S -> Ladungsmatrix \(\Sigma\)
- Modellevaluation
- Bestimmung der Anzahl der latenten Variablen
- Parallelanalyse -> Nutzt die Eigenwerte von steigender Anzahl an Faktoren, um plausible Anzahl an Faktoren zu ermitteln
- Wahl einer angemessenen Rotationstechnik
- Mehrere gleichwertige Lösungen -> Mit Rotation (Promax, oblimin) auf eine festlegen
Modellevaluation
Hypothesentest
Value of Fitting-Function (VFF): Minimale Diskrepanz nach fitting
Die Teststatistik
\[\large \chi_{e m p}^{2}=V F F \cdot(n-1)\], verteilt nach Chi-Quadrat mit df = bekannte Größen - unbekannte Größen, prüft
\(\Sigma\) Modell Population \(=S\) Population
oder
\(P\) Modell Population \(=R\) Population
Fit-Indizes
Diese Angaben sind grobe Richtwerte für ML-Methode:
- Abweichung von best fit (Ideale Werte sind 0)
- SRMR Standardized-Squared-Mean-Residual \(\leq 0.11\)
- RMSEA Root-Mean-Square-Error-of-Approximation \(\leq 0.08(n<250)\) und unter \(\leq 0.06(n>250)\)
- Abweichung vom worst fit (Ideale Werte sind 1)
- CFI Comparative Fit Index \(\geq 0.95\)
Andere Methode: Bayes Information Criterion, (BIC): wie gut das Modell passt, wie groß die Stichprobe ist und wie komplex das Modell ist
\[\large B I C=\chi_{e m p}^{2}+\ln (n)+n_{p}\] * \(n=\) Stichprobengröße * \(n_{p}=\) unbekannte Modellgrößen / zu schätzende Modellparameter
Passendstes und sparsamstes Modell-> kleinsten Wert aller betrachteten Modelle wählen
Lokaler Fit
Sogenannte Modifikationsindizes (mi) prüfen, an welchen Stellen die Freisetzung eines Parameters zu einer signifikanten Modellverbesserung führt (strenge des Modells lokal verringern)
- Bei einem Freiheitsgrad sind 3.84 Chi-Quadrat-Punkte notwendig, damit das Modell signifikant verbessert werden kann
- Prüfung lokaler Fit (mi ≥ 3.84) -> Freisetzung
Rotation
Anfangslösung (Faktormatrix)

Rotierte Lösung (Mustermatrix)
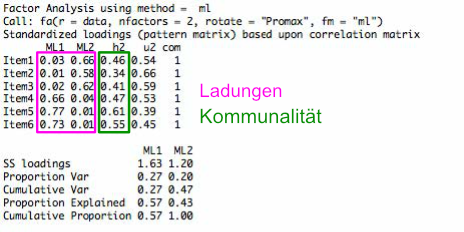
Reliabilität
Die Reliabilität beschreibt die Genauigkeit bzw. Zuverlässigkeit (DIN 33430), mit der ein psychologischer Test ein Merkmal erfasst
unabhängig von der Einheit des Items
Einzelnes Item
\[\large REL\left(X_{i}\right)=\frac{\operatorname{VAR}\left(\tau_{i}\right)}{\operatorname{VAR}\left(X_{i}\right)}=\frac{\operatorname{VAR}\left(\tau_{i}\right)}{\operatorname{VAR}\left(\tau_{i}\right)+\operatorname{VAR}\left(\varepsilon_{i}\right)}\] \[\large 0 \leq R E L\left(X_{i}\right) \leq 1\]
\(\large \operatorname{VAR}(\varepsilon_{i}) = 0 \implies R E L\left(X_{i}\right)= 1\)
\(\large \lim_{\operatorname{VAR}\left(\varepsilon_{i}\right) \rightarrow \infty} R E L\left(X_{i}\right)=0\)
Itemmittelwert und Itemsumme
\[ \large R E L(\bar{X})=\frac{V A R\left(\frac{1}{k} \sum_{i=1}^{k} \tau_{i}\right)}{V A R\left(\frac{1}{k} \sum_{i=1}^{k} X_{i}\right)} = \frac{\operatorname{VAR}\left(\sum_{i=1}^{k} \tau_{i}\right)}{\operatorname{VAR}\left(\sum_{i=1}^{k} X_{i}\right)}=R E L\left(\sum_{i=1}^{k} X_{i}\right)\]
Cronbachs Alpha:
\[ \large \alpha=\frac{k}{k-1} \cdot\left(1-\frac{\sum_{i=1}^{k} \operatorname{VAR}\left(X_{i}\right)}{\operatorname{VAR}\left(\sum_{i=1}^{k} X_{i}\right)}\right) \]
# example data: 4 people answered
data = cbind(
c(4, 5, 7, 5), # item1 - column 1
c(1, 1, 2, 1), # item2 - column 2
c(1, 2, 2, 1) # item3 - column 3
)
k = ncol(data)
vars_per_item = apply(data, 2, var)
answer_sums_per_person = rowSums(data)
k/(k-1)* (1-sum(vars_per_item)/var(answer_sums_per_person)) Spearman Brown:
\[\large R E L(\bar{X})=\frac{k^{2}}{k(k-1)+\sum_{i=1}^{k} \frac{1}{R E L\left(X_{i}\right)}} = \alpha\]
rel_items <- c(0.7, 0.9, 0.6)
k = length(rel_items)
k*k/(k*(k-1) + sum(1/rel_items))paralleles Modell, essentiell paralleles Modell
Einzelnes Item
\[\large R E L\left(X_{i}\right)=\operatorname{COR}\left(X_{i}, X_{j}\right)=\operatorname{COR}\left(X_{j}, X_{i}\right)=R E L\left(X_{j}\right)\]
# Schätzung konkret: Durchschnitt der Korrelationen über alle Paare
cormatrix = rbind(
c(NA , 0.8, 0.6),
c(NA , NA , 0.7),
c(NA , NA , NA )
)
n = dim(cormatrix)[[1]]
sum_cor = 0
for(i in 1:(n-1)){
for (j in (i+1):n){
sum_cor = sum_cor + cormatrix[[i,j]]
}
}
rel_items = (rep(sum_cor, n)/n)
for (i in 1:n){
print(paste("Item ",i,": ",rel_items[[i]]))
}Itemmittelwert
Cronbachs alpha, Spearman Brown - vereinfacht, da die Rels für alle Items gleich sind:
\[\large \operatorname{REL}(\bar{X})=\frac{k}{(k-1)+\frac{1}{R E L\left(X_{i}\right)}}\]cormatrix = rbind(
c(NA , 0.8, 0.6),
c(NA , NA , 0.7),
c(NA , NA , NA )
)
k = dim(cormatrix)[[1]]
sum_cor = 0
for(i in 1:(k-1)){
for (j in (i+1):k){
sum_cor = sum_cor + cormatrix[[i,j]]
}
}
rel_items = (rep(sum_cor, k)/k)
k/(k-1+(1/rel_items[[1]]))Jedes Item erhöht die Reliabilität des Itemmittelwerts!
tau-äquivalentes Modell, essentiell tau-äquivalentes Modell
Einzelnes Item
\[REL\left(X_{i}\right)=\frac{\operatorname{COV}\left(X_{i}, X_{j}\right)}{\operatorname{VAR}\left(X_{i}\right)}\] nicht symmetrisch!
# Schätzung konkret: Durchschnitt der korrelationen über alle Paare DURCH jeweilige Varianz des Items
covmatrix = rbind(
c(2 , 1.4, 1.5),
c(NA , 3 , 1 ),
c(NA , NA , 10 )
)
n = dim(covmatrix)[[1]]
sum_cov = 0
for(i in 1:(n-1)){
for (j in (i+1):n){
sum_cov = sum_cov + covmatrix[[i,j]]
}
}
rel_items = (rep(sum_cov, n)/n)/diag(covmatrix)
for (i in 1:n){
print(paste("Item ",i,": ",rel_items[[i]]))
}Itemmittelwert
Spearman Brown, Cronbachs alpha
covmatrix = rbind(
c(2 , 1.4, 1.5),
c(NA , 3 , 1 ),
c(NA , NA , 10 )
)
k = dim(covmatrix)[[1]]
sum_cov = 0
for(i in 1:(k-1)){
for (j in (i+1):k){
sum_cov = sum_cov + covmatrix[[i,j]]
}
}
rel_items = (rep(sum_cov, k)/k)/diag(covmatrix)
k*k/(k*(k-1) + sum(1/rel_items))t-kongenerisches Modell
Einzelnes Item
\[R E L\left(X_{i}\right)=\beta_{z i}^{2}\]
# Schätzung konkret
beta_z = c(0.246, 0.866, 0.879, 0.514) # "Latent Variables: Std.all"
rel_items = beta_z^2
for (i in 1:length(rel_items)){
print(paste("Item ",i,": ",rel_items[[i]]))
}Itemmittelwert
McDonalds’s Omega (i’m lovin’ it):
\[\large \omega=\frac{\left(\sum_{i=1}^{k} \beta_{i}\right)^{2}}{V A R\left(\sum_{i=1}^{k} X_{i}\right)}\]# needs both data and betas as input -> never really calculated by hand
# example data: 4 people answered
data = cbind(
c(4, 5, 7, 5), # item1 - column 1
c(1, 1, 2, 1), # item2 - column 2
c(1, 2, 2, 1) # item3 - column 3
)
betas = c(0.6, 0.8, 0.7)
k = ncol(data)
vars_per_item = apply(data, 2, var)
answer_sums_per_person = rowSums(data)
(sum(betas))^2/var(answer_sums_per_person)Cronbachs Alpha bietet eine untere Schranke für die Reliabilität
\[ \large \alpha \leq \omega=\operatorname{REL}(\bar{X}) \]
McDonald’s Omega kann überall dort verwendet werden, wo auch Cronbachs Alpha verwendet wird, benötigt aber Werte aus einer Faktorenanalyse
Mehrdimensional t-kongenerisches Modell
Einzelnes Item
\[R E L\left(X_{i}\right)=\sum_{l=1}^{q} \beta_{z i l}^{2}\] Kann auch aus der Anfangslösung der Faktorenanalyse berechnet werden -> entspricht der Kommunalität (h2)
Itemmittelwert
Wenn Einfachstruktur -> mehrere eindimensionale t-kongenerische Modelle
Allgemeine Methoden
Achtung: Kovarianzgleichheit der einzelnen Items kann in beiden Fällen nicht überprüft werden
Split-Half Methode
Zwei Items: Mittelwert je einer Testhälfte
\[\large \bar{X}=\frac{1}{2}\left(\bar{X}_{1}+\bar{X}_{2}\right)\] Falls diese parallel oder essentiell parallel: Vereinfachung der Spearman Brown Formel
\[\large R E L(\bar{X})=\frac{2}{(2-1)+\frac{1}{R E L\left(\bar{X}_{i}\right)}} =\frac{2 \cdot \operatorname{COR}\left(\bar{X}_{1}, \bar{X}_{2}\right)}{\operatorname{COR}\left(\bar{X}_{1}, \bar{X}_{2}\right)+1}\]
corrAB <- 0.7
(2*corrAB)/(corrAB+1)Paralleltest-Methode
Ergebnisse zweier Tests liegen vor, bilden jeweils ein Item
\[\large REL\left(X_{i}\right)=\operatorname{COR}\left(X_{1}, X_{2}\right)\]
x1 = c(1,1,1,2,2)
x2 = c(1,2,3,4,5)
cor(x1,x2)Validität
Die Validität gibt an, ob ein psychologischer Test auch wirklich das misst, was er zu messen beansprucht
Faktorielle Validität
- Zusammenhänge latente Variablen eines Tests untereinander
Sind die Korrelationen zwischen den latenten Variablen \(\theta_{A 1}, \theta_{A 2}, \theta_{A 3}\) des Tests \(A\) mit der psychologischen Theorie vereinbar?
\[\large \operatorname{COR}\left(\theta_{A 1}, \theta_{A 2}\right)\]

Konstruktvalidität
- Zusammenhänge latente Variablen mehrerer Tests
Sind die Korrelationen zwischen der latenten Variable \(\theta_{A 1}\) des Tests \(A\) und den latenten Variablen \(\theta_{B}, \theta_{C}\) anderer Tests \(B, C\) mit der psychologischen Theorie vereinbar?
\[\large \operatorname{COR}\left(\theta_{A 1}, \theta_{B}\right)\]
Zusätzliche Annahme: Die Fehler müssen nicht nur innerhalb, sondern auch über beide Tests A, B hinweg unkorreliert sein.
Weitere förderliche Bedingungen:
Die theoretisch angenommene Anzahl an Faktoren entspricht dem Ergebnis der Parallelanalyse (oder anderer Methode zur Bestimmung der Faktorenanzahl)
Es liegt eine Einfachstruktur vor
Die Faktoren können inhaltlich im Sinne der Theorie interpretiert werden, d.h. alle Items eines Tests sind eindeutig den latenten Variablen ihres Tests zuordenbar
Doppelte Minderungskorrektur
Annahme: tau-kongenerisches Modell oder strenger
\[\large \operatorname{COR}\left(\theta_{A}, \theta_{B}\right)=\frac{\operatorname{COR}\left(\sum_{i=1}^{k_{A}} X_{i A}, \sum_{j=1}^{k_{B}} X_{j B}\right)}{\sqrt{R E L\left(\sum_{i=1}^{k_{A}} X_{i A}\right) \cdot \operatorname{REL}\left(\sum_{j=1}^{k_{B}} X_{j B}\right)}}\]cor_ab = 0.38
relA = 0.65
relB = 0.81
(cor_ab)/sqrt(relA*relB)Kriteriumsvalidität
- Zusammenhänge latente Variablen und messfehlerfreie Variablen
Sind die Korrelationen zwischen den latenten Variablen \(\theta_{A 1}\), \(\theta_{A2}\) des Tests A und (messfehlerfreien) manifesten Variablen (sogenannten Kriterien) K1, K2 mit der psychologischen Theorie vereinbar?
\[\large \operatorname{COR}\left(\theta_{A 1}, K_{1}\right)\]
Einfache Minderungskorrektur
Annahme: tau-kongenerisches Modell oder strenger
\[\large \operatorname{COR}\left(\theta_{A}, K\right)=\frac{\operatorname{COR}\left(\sum_{i=1}^{k_{A}} X_{i A}, K\right)}{\sqrt{R E L\left(\sum_{i=1}^{k_{A}} X_{i A}\right)}}\]
cor_ak = 0.38
relA = 0.65
(cor_ak)/sqrt(relA)Einzelfalldiagnostik
\[\large X_{i P e r s o n}=\sigma_{i}+\beta_{i} \cdot \theta_{P e r s o n}+\varepsilon_{i P e r s o n} \]
\(X_{i P e r s o n}\): Zufallsvariable, die für die Itemantwort der festen Person steht
\(\theta_{\text {Person }}\): unbekannte Konstante
\(\sigma_{i}\) und \(\beta_{i}\): Parameter des Modells, für die schon Schätzwerte aus der Normstichprobe vorliegen
zwischen \(\varepsilon_{i}\) auf der Ebene der zufälligen Person und \(\varepsilon_{i P e r s o n}\) auf der Ebene der festen Person gibt es zwar mathematisch gesehen einen geringfügigen Unterschied, der für uns jedoch nicht relevant ist
Standardmessfehler
\[ \large \operatorname{SE}\left(\hat{\theta}_{\text {Person }}\right)=\sqrt{V A R\left(\hat{\theta}_{\text {Person }}\right)}\]
Konfidenzintervall
\[\large I\left(X_{1 \text { Person }}, X_{2 \text { Person }}, \ldots, X_{k \text { Person }}\right)=\left[\hat{\theta}_{\text {Person }} \pm Z_{1-\frac{\alpha}{2}} \cdot S E\left(\hat{\theta}_{\text {Person }}\right)\right]\]
Normwerte
| Name | \(E\left(\theta_{\text {Norm }}\right)\) | \(\operatorname{STD}\left(\theta_{\text {Norm }}\right)\) | |
|---|---|---|---|
| Z-Werte | 0 | 1 | |
| IQ-Werte | 100 | 15 | |
| Standardwerte | 100 | 10 | |
| T-Werte | 50 | 10 | |
| Stanine | 5 | 2 |
KI, falls man Punktschätzwerte in Normwerte umrechnet: \[\large \left[\hat{\theta}_{\text {Person,Norm }} \pm z_{1-\frac{\alpha}{2}} \cdot \widehat{S E}\left(\hat{\theta}_{\text {Person,Norm }}\right)\right]\] Besser: Normalisieren der Werte (tau-kongenerisch sind bereits normiert), dann Werte umrechnen:
\[\large \hat{\theta}_{\text {Person, } z-\text { Wert }}=\frac{\hat{\theta}_{\text {Person,Wert }}-E(\theta)}{\sqrt{\operatorname{VAR}(\theta)}}\]
\[\large E\left(\theta_{z}\right)=0 \text { und } V A R\left(\theta_{z}\right)=1\]
est_person = 20
est_theta = 10
var_theta = 5
(est_person-est_theta)/sqrt(var_theta)norm_mean = 100
norm_std = 15
z_theta_pers = 0.5
norm_mean + norm_std * z_theta_persSchätzung Standardmessfehler mit unvollständigen Informationen:
\[\large \widehat{S E}\left(\hat{\theta}_{\text {PersonNorm }}\right)_{\text {Wert }}=\sqrt{\operatorname{VAR}\left(\theta_{\text {Norm }}\right) \cdot(1-\operatorname{rel}(\bar{x}))}\] Prozentränge (% der Personen, die einen gleichen oder niedrigeren Wert auf der Latenten Variable haben):
z_theta_pers = 0.5
norm_mean = 100
norm_std = 15
pnorm(norm_mean + norm_std * z_theta_pers, mean=norm_mean, sd=norm_std)Paralleles Modell
\[\large \hat{\theta}_{\text {Person }}=\frac{1}{k} \sum_{i=1}^{k} X_{i \text { Person }}\]items_pers = c(70,50,60,50)
mean(items_pers)k = 4 # number of items
item_var_pers = 24.352 # "Variances: ", alle identisch
sqrt(item_var_pers/k)# Konfidenzintervall
items_pers = c(70,50,60,50)
item_var_pers = 24.352 # "Variances: ", alle identisch
conf.level = 0.95
k = length(items_pers)
est_pers = mean(items_pers)
stderr_pers = sqrt(item_var_pers/k)
c = stderr_pers * qnorm(1-(1-conf.level)/2)
c(est_pers - c, est_pers + c)# Gegebenes Konfidenzintervall -> Normwerte
lower_limit_pers = 12
higher_limit_pers = 14
est_theta = 10 # Intercepts: f Estimate
var_theta = 5 # Variances: f Estimate
norm_mean = 100
norm_std = 15
z_lower_limit_pers = (lower_limit_pers-est_theta)/sqrt(var_theta)
z_higher_limit_pers = (higher_limit_pers-est_theta)/sqrt(var_theta)
c(norm_mean + norm_std * z_lower_limit_pers, norm_mean + norm_std * z_higher_limit_pers)Essentiell paralleles Modell
\[\large \hat{\theta}_{\text {Person }}=\frac{1}{k} \sum_{i=1}^{k} X_{i \text { Person }}-\frac{1}{k} \sum_{i=1}^{k} \sigma_{i}\]items_pers = c(70,50,60,50)
sigmas = c(10, 30, 40, 5) # Intercepts:
mean(items_pers) - mean(sigmas)\[\large S E\left(\hat{\theta}_{\text {Person }}\right)=\sqrt{\frac{V A R\left(\varepsilon_{i}\right)}{k}}\]
k = 4 # number of items
item_var_pers = 24.352 # "Variances: ", alle identisch
sqrt(item_var_pers/k)# Konfidenzintervall
items_pers = c(70,50,60,50)
item_var_pers = 24.352 # "Variances: ", alle identisch
sigmas = c(10, 30, 40, 5) # Intercepts:
conf.level = 0.95
k = length(items_pers)
est_pers = mean(items_pers) - mean(sigmas)
stderr_pers = sqrt(item_var_pers/k)
c = stderr_pers * qnorm(1-(1-conf.level)/2)
c(est_pers - c, est_pers + c)# Gegebenes Konfidenzintervall -> Normwerte
lower_limit_pers = -3
higher_limit_pers = 2
var_theta = 5 # Variances: f Estimate
norm_mean = 100
norm_std = 15
z_lower_limit_pers = (lower_limit_pers)/sqrt(var_theta)
z_higher_limit_pers = (higher_limit_pers)/sqrt(var_theta)
c(norm_mean + norm_std * z_lower_limit_pers, norm_mean + norm_std * z_higher_limit_pers)Tau-äquivalentes Modell
\[ \large \hat{\theta}_{\text {Person }}=\frac{\sum_{i=1}^{k} \frac{X_{i P e r s o n}}{V A R\left(\varepsilon_{i}\right)}}{\sum_{i=1}^{k} \frac{1}{V A R\left(\varepsilon_{i}\right)}} \]
items_pers = c(5,4,5,4)
item_vars_pers = c(0.043, 0.495, 0.972, 0.080)
sum(items_pers/item_vars_pers)/sum(1/item_vars_pers)\[\large S E\left(\hat{\theta}_{\text {Person }}\right)=\frac{1}{\sqrt{\sum_{i=1}^{k} \frac{1}{V A R\left(\varepsilon_{i}\right)}}}\]
item_vars_pers = c(0.043, 0.495, 0.972, 0.080)
1/sqrt(sum(1/item_vars_pers))# Konfidenzintervall
items_pers = c(5,4,5,4)
item_vars_pers = c(0.043, 0.495, 0.972, 0.080) # "Variances: "
conf.level = 0.95
est_pers = sum(items_pers/item_vars_pers)/sum(1/item_vars_pers)
stderr_pers = 1/sqrt(sum(1/item_vars_pers))
c = stderr_pers * qnorm(1-(1-conf.level)/2)
c(est_pers - c, est_pers + c)# Gegebenes Konfidenzintervall -> Normwerte
lower_limit_pers = 12
higher_limit_pers = 14
est_theta = 10 # Intercepts: f Estimate
var_theta = 5 # Variances: f Estimate
norm_mean = 100
norm_std = 15
z_lower_limit_pers = (lower_limit_pers-est_theta)/sqrt(var_theta)
z_higher_limit_pers = (higher_limit_pers-est_theta)/sqrt(var_theta)
c(norm_mean + norm_std * z_lower_limit_pers, norm_mean + norm_std * z_higher_limit_pers)Essentiell tau-äquivalentes Modell
\[\large \hat{\theta}_{\text {Person }}=\frac{\sum_{i=1}^{k} \frac{X_{i P e r s o n}-\sigma_{i}}{V A R\left(\varepsilon_{i}\right)}}{\sum_{i=1}^{k} \frac{1}{V A R\left(\varepsilon_{i}\right)}}\]
items_pers = c(5,4,5,4)
item_vars_pers = c(0.043, 0.495, 0.972, 0.080) # "Variances: "
intercepts = c(1.091, 2.123, 2.618, 4.086) # Intercepts:
sum((items_pers-intercepts)/item_vars_pers)/sum(1/item_vars_pers)\[\large \operatorname{SE}\left(\hat{\theta}_{\text {Person }}\right)=\frac{1}{\sqrt{\sum_{i=1}^{k} \frac{1}{V A R\left(\varepsilon_{i}\right)}}}\]
item_vars_pers = c(0.043, 0.495, 0.972, 0.080) # "Variances: "
1/sqrt(sum(1/item_vars_pers))# Konfidenzintervall
items_pers = c(5,4,5,4)
item_vars_pers = c(0.043, 0.495, 0.972, 0.080) # "Variances: "
intercepts = c(1.091, 2.123, 2.618, 4.086) # Intercepts:
conf.level = 0.95
est_pers = sum((items_pers-intercepts)/item_vars_pers)/sum(1/item_vars_pers)
stderr_pers = 1/sqrt(sum(1/item_vars_pers))
c = stderr_pers * qnorm(1-(1-conf.level)/2)
c(est_pers - c, est_pers + c)# Gegebenes Konfidenzintervall -> Normwerte
lower_limit_pers = -3
higher_limit_pers = 2
var_theta = 5 # Variances: f Estimate
norm_mean = 100
norm_std = 15
z_lower_limit_pers = (lower_limit_pers)/sqrt(var_theta)
z_higher_limit_pers = (higher_limit_pers)/sqrt(var_theta)
c(norm_mean + norm_std * z_lower_limit_pers, norm_mean + norm_std * z_higher_limit_pers)Tau-kongenerisches Modell
\[\large Z_{i \text { Person }}=\frac{X_{i \text { Person }}-E\left(X_{i}\right)}{\sqrt{\operatorname{VAR}\left(X_{i}\right)}}=\frac{X_{i \text { Person }}-\sigma_{i}}{\sqrt{\operatorname{VAR}\left(X_{i}\right)}}\]items_pers = c(3,1,3,2)
item_vars_pers = c(1, 1.1, 2, 1.2) # Nicht ablesbar aus Normstichprobe!
intercepts = c(1.033, 2.002, 2.495, 4.014) # Intercepts:
(items_pers - intercepts)/sqrt(item_vars_pers)items_pers = c(3,1,3,2)
item_vars_pers = c(1, 1.1, 2, 1.2) # Nicht ablesbar aus Normstichprobe!
intercepts = c(1.033, 2.002, 2.495, 4.014) # Intercepts:
beta_z = c(0.995, 0.576, 0.703, 0.981) # "Latent Variables: Std.all"
z_items_pers = (items_pers - intercepts)/sqrt(item_vars_pers)
sum((beta_z*z_items_pers)/(1-beta_z^2))/sum(beta_z^2/(1-beta_z^2))\[\large S E\left(\hat{\theta}_{\text {Person }}\right)=\frac{1}{\sqrt{\sum_{i=1}^{k} \frac{\beta_{z i}^{2}}{1-\beta_{z i}^{2}}}}\]
items_pers = c(3,1,3,2)
item_vars_pers = c(1, 1.1, 2, 1.2) # Nicht ablesbar aus Normstichprobe!
intercepts = c(1.033, 2.002, 2.495, 4.014) # "Intercepts: "
beta_z = c(0.995, 0.576, 0.703, 0.981) # "Latent Variables: Std.all"
z_items_pers = (items_pers - intercepts)/sqrt(item_vars_pers)
1/sqrt(sum(beta_z^2/(1-beta_z^2)))# Konfidenzintervall
items_pers = c(3,1,3,2)
item_vars_pers = c(1, 1.1, 2, 1.2) # Nicht ablesbar aus Normstichprobe!
intercepts = c(1.033, 2.002, 2.495, 4.014) # "Intercepts: "
beta_z = c(0.995, 0.576, 0.703, 0.981) # "Latent Variables: Std.all"
conf.level = 0.95
z_items_pers = (items_pers - intercepts)/sqrt(item_vars_pers)
est_pers = sum((beta_z*z_items_pers)/(1-beta_z^2))/sum(beta_z^2/(1-beta_z^2))
stderr_pers = 1/sqrt(sum(beta_z^2/(1-beta_z^2)))
c = stderr_pers * qnorm(1-(1-conf.level)/2)
c(est_pers - c, est_pers + c)# Gegebenes Konfidenzintervall -> Normwerte
lower_limit_pers = 0.5 # Bereits Z standardisiert
higher_limit_pers = 1.0 # Bereits Z standardisiert
norm_mean = 100
norm_std = 15
c(norm_mean + norm_std * lower_limit_pers, norm_mean + norm_std * higher_limit_pers)Mehrdimensionales tau-kongenerisches Modell
Einfachstruktur -> aufteilen und mehrere eindimensionale tau-kongenerische Modelle betrachten
Approximative Konfidenzintervalle
Wenn modellbasierte Konstuktion eines Konfidenzintervalls nicht möglich ist (Standardmessfehler und/oder Parameter nicht angegeben) Konfidenzintervalle hier deutlich breiter
\[\large S E\left(\hat{\theta}_{\text {Person }}\right)=\sqrt{\operatorname{VAR}(X) \cdot(1-\operatorname{Rel}(X))}\]var_norm = 0.04
rel = 0.8
sqrt(var_norm*(1-rel))Normorientierte Interpretation KI
\[\large I\left(X_{1 \text { Person }}, X_{2 \text { Person }}, \ldots, X_{k \text { Person }}\right)=[UP,OP]\]
Intervall der Werte, die als “Durchschnitt” zählen:
\[\large [E(\theta)-\sqrt{\operatorname{VAR}(\theta)}, E(\theta)+\sqrt{\operatorname{VAR}(\theta)} ] = [UD, OD] \]
\(OP < UD \implies\) unterdurchschnittlich
\(UP < UD < OP \land OP < OD \implies\) unterdurchschnittlich bis durchschnittlich
\(UD < UP \land OP < OD \implies\) durchschnittlich
\(UD < UP < OD \land OD < OP \implies\) durchschnittlich bis überdurchschnttlich
\(UD < UP \implies\) überdurchschnittlich
var_norm = 0.04
est_norm = 0.8
lower_limit_pers = 0.4
higher_limit_pers = 0.7
lower_limit_normavg = est_norm - sqrt(var_norm)
higher_limit_normavg = est_norm + sqrt(var_norm)
paste("Avg Intervall: [",lower_limit_normavg,";",higher_limit_normavg,"]")
if(higher_limit_pers < lower_limit_normavg){print("unterdurchschnittlich")
}else if(
lower_limit_pers < lower_limit_normavg &
lower_limit_normavg < higher_limit_pers &
higher_limit_pers < higher_limit_normavg
){print("unterdurchschnittlich bis durchschnittlich")
}else if(
lower_limit_normavg < lower_limit_pers &
higher_limit_pers < higher_limit_normavg
){print("durchschnittlich")
}else if(
lower_limit_normavg < lower_limit_pers &
lower_limit_pers < higher_limit_normavg &
higher_limit_normavg < higher_limit_pers
){print("durchschnittlich bis überdurchschnittlich")
} else if(higher_limit_normavg < lower_limit_pers){print("überdurchschnittlich")
} else {print("Check input for errors")}Hypothesentest
\[\large Z \sim N(0,1)\]
Unterschied von vorgegebenem Wert
\[\large Z=\frac{\hat{\theta}_{\text {Person }}-\theta_{0}}{\operatorname{SE}\left(\hat{\theta}_{\text {Person }}\right)} \]
theta0 = 67.5
est_pers = 57.5
stderr_pers = 2.47
(est_pers-theta0)/stderr_pers\[ \large \begin{aligned} &H_{0}: \theta_{\text {Person }}=\theta_{0} \\ &H_{1}: \theta_{\text {Person }} \neq \theta_{0} \end{aligned}\]
# Hypothesentest von Hand - Beidseitig
alpha = 0.05
theta0 = 50
est_pers = 57.5
stderr_pers = 2.47
klinks = qnorm(alpha/2)
krechts = qnorm(1-(alpha/2))
paste("Krit. Bereich: ]-INF;", klinks,"] [", krechts, "; INF[", sep="")
z = (est_pers-theta0)/stderr_pers
paste("Realisierung Teststatistik: ",z)
p = if(z <= 0) 2*pnorm(z) else 2*pnorm(-z)
paste("p-Wert: ", p)
if(p <= alpha) print("H1 annehmen") else print("H0 annehmen")\[ \large \begin{aligned} &H_{0}: \theta_{\text {Person }} \leq \theta_{0} \\ &H_{1}: \theta_{\text {Person }}>\theta_{0} \end{aligned} \]
# Hypothesentest von Hand - Rechtsgerichtet
alpha = 0.05
theta0 = 50
est_pers = 57.5
stderr_pers = 2.47
krechts = qnorm(1-alpha)
paste("Krit. Bereich: [", krechts,";INF[", sep="")
z = (est_pers-theta0)/stderr_pers
paste("Realisierung Teststatistik: ",z)
p = 1-pnorm(z)
paste("p-Wert: ", p)
if(p <= alpha) print("H1 annehmen") else print("H0 annehmen")\[ \large \begin{aligned} &H_{0}: \theta_{\text {Person }} \geq \theta_{0} \\ &H_{1}: \theta_{\text {Person }}<\theta_{0} \end{aligned} \]
# Hypothesentest von Hand - Linksgerichtet
alpha = 0.05
theta0 = 50
est_pers = 57.5
stderr_pers = 2.47
klinks = qnorm(alpha)
paste("Krit. Bereich: ] -INF;", klinks,"]", sep="")
z = (est_pers-theta0)/stderr_pers
paste("Realisierung Teststatistik: ",z)
p = pnorm(z)
paste("p-Wert: ", z)
if(p <= alpha) print("H1 annehmen") else print("H0 annehmen")Unterschied zwei Personen
\[\large Z=\frac{\hat{\theta}_{\text {Person } 1}-\hat{\theta}_{\text {Person } 2}}{\sqrt{2} \cdot S E\left(\hat{\theta}_{\text {Person }}\right)} \]est_pers1 = 67.5
est_pers2 = 57.5
stderr_pers = 2.47
(est_pers1-est_pers2)/(sqrt(2)*stderr_pers)\[\large \begin{aligned} &H_{0}: \theta_{\text {Person } 1}=\theta_{\text {Person } 2} \\ &H_{1}: \theta_{\text {Person } 1} \neq \theta_{\text {Person } 2} \end{aligned} \]
# Hypothesentest von Hand - Beidseitig
alpha = 0.05
est_pers1 = 67.5
est_pers2 = 57.5
stderr_pers = 2.47
klinks = qnorm(alpha/2)
krechts = qnorm(1-(alpha/2))
paste("Krit. Bereich: ]-INF;", klinks,"] [", krechts, "; INF[", sep="")
z = (est_pers1-est_pers2)/(sqrt(2)*stderr_pers)
paste("Realisierung Teststatistik: ",z)
p = if(z <= 0) 2*pnorm(z) else 2*pnorm(-z)
paste("p-Wert: ", p)
if(p <= alpha) print("H1 annehmen") else print("H0 annehmen")# Hypothesentest von Hand - Rechtsgerichtet
alpha = 0.05
est_pers1 = 67.5
est_pers2 = 57.5
stderr_pers = 2.47
krechts = qnorm(1-alpha)
paste("Krit. Bereich: [", krechts,";INF[", sep="")
z = (est_pers1-est_pers2)/(sqrt(2)*stderr_pers)
paste("Realisierung Teststatistik: ",z)
p = 1-pnorm(z)
paste("p-Wert: ", p)
if(p <= alpha) print("H1 annehmen") else print("H0 annehmen")\[\large \begin{aligned} &H_{0}: \theta_{\text {Person } 1}\geq\theta_{\text {Person } 2} \\ &H_{1}: \theta_{\text {Person } 1} < \theta_{\text {Person } 2} \end{aligned} \]
# Hypothesentest von Hand - Linksgerichtet
alpha = 0.05
est_pers1 = 67.5
est_pers2 = 57.5
stderr_pers = 2.47
klinks = qnorm(alpha)
paste("Krit. Bereich: ] -INF;", klinks,"]", sep="")
z = (est_pers1-est_pers2)/(sqrt(2)*stderr_pers)
paste("Realisierung Teststatistik: ",z)
p = pnorm(z)
paste("p-Wert: ", p)
if(p <= alpha) print("H1 annehmen") else print("H0 annehmen")